
前言
當錄製好一段影片後,想要為影片加上字幕,該怎麼快速進行?
或是透過 iPhone 錄製好開會紀錄的對話、訪談內容後,如何將其轉換為可閱讀的文字稿?
當影片講述內容過於艱深或遇到語言障礙,如何把影片丟給 AI 進行分析後有條理的統整、並告知原因與結果?
上述需求,都可透過 OpenAI 開源的 Whisper 自動語音辨識模型,或其高效衍生專案 Faster-Whisper,在本地端完成部署與操作,實現影片/音訊的一鍵轉文字、字幕產生與後續內容分析。
什麼是 Whisper?
Whisper 是在 2022 年 9 月由 OpenAI 正式發表並開源的語音辨識系統(automatic speech recognition,ASR)。截至 2025 年,Whisper 已經問世將近 3 年。
主要功能
語音轉文字:可將錄音、影片等語音內容自動辨識並轉換為文字逐字稿。
多語言支援:支援超過 57 種語言(如中英日法等),並具備自動語言偵測能力。底層模型實際以 98 種語言資料進行弱監督式訓練,官方僅對「字錯率低於 50%」的 57 種語言提供保證支援。
自動語言辨識:無需預先指定語言,模型可自動判斷語音所使用的語言。
強大容錯能力:即使音質不佳、口音重或有背景雜訊,仍能維持較高辨識準確度。
技術特點
深度學習模型:採用 Transformer 架構,並以大規模多語言語音轉文字對應資料進行弱監督式訓練。
開源可得:原始碼與模型權重皆免費開放於 GitHub,方便研究者與開發者進行二次開發與客製化。
跨平台支援:可在 Windows、macOS、Linux 等多種作業系統中部署。
多種模型尺寸:提供從
tiny到large-v3、turbo等多種模型配置,可依資源與精確度需求做選擇。
應用場景
影片字幕自動產生:快速產生影片逐字稿與字幕檔(SRT/TXT)。
會議記錄自動化:將線上/線下會議錄音語音轉文字,減少人工整理時間。
語音搜尋與語音控制:支援語音查詢、命令辨識等使用場景。
Podcast、訪談轉錄:將長篇語音內容快速語音轉文字稿,利於內容管理與尋找。
其他版本
除了原始 Whisper 模型外,社群還衍生出多個專案,以因應不同的效能與功能需求:
faster-whisper:基於 Whisper 架構,採用 CTranslate2 作為推論引擎重寫,大幅提升執行速度與資源效率,適合需要高吞吐量或即時轉錄的應用場景。
WhisperX:在 faster-whisper 基礎上加入批次推論、強制對齊(forced alignment)、語者分離(diarization)、語音活動偵測(VAD)等進階功能,特別適用於長音檔或多說話人錄音的精準轉錄與分析。
Whisper.cpp:將 Whisper 模型以超輕量級 C/C++ 實現,可在各類邊緣裝置(如筆電、手機、IoT)中本地離線運行,並快速啟動,適合對即時性與可攜性要求極高的場景。
先前我在轉字幕,都是使用 OpenAI 官方 Whisper 進行影片字幕轉錄,但後來發現 faster-whisper 在相同硬體資源下,不僅可達到相當或更佳的辨識精度,且運算時間明顯縮短。因此,本次教學優先採用 faster-whisper;若未來需更高對齊精度或多說話者分析,可再評估導入 WhisperX。
於本地部署 faster-whisper
安裝 Python
需要安裝 Python 3.9 或更新的版本,在此直接透過 WinGet 進行安裝:
| |
透過 python -V 檢查版本,有回傳版本號表示安裝成功:
| |
安裝 faster-whisper
| |
安裝 CUDA Toolkit 12 與 cuDNN(選擇性)
⚠️ 本步驟僅適用於搭載 NVIDIA 顯示卡且支援 CUDA 的系統。
若使用支援 CUDA 的 GPU,可大幅加速模型轉換處理流程,顯著縮短所需時間。以下為支援 CUDA 的 NVIDIA GPU 型號整理:
| 類別 | 型號 |
|---|---|
| 資料中心與超級晶片 | B200, B100, GH200, H200, H100, L40S, L40, L4, A100, A40, A30, A16, A10, A2, T4, V100 |
| 工作站與專業卡 | RTX PRO 6000, RTX PRO 5000, RTX PRO 4500, RTX PRO 4000, RTX 6000, RTX 5000, RTX 4500, RTX 4000, RTX 2000, RTX A6000, RTX A5500, RTX A5000, RTX A4500, RTX A4000, RTX A2000, Quadro RTX 8000/6000/5000/4000, Quadro GV100, Quadro T-Series |
| GeForce | RTX 50: 5090, 5080, 5070 Ti, 5070, 5060 Ti, 5060 <br> RTX 40: 4090, 4080, 4070 SUPER/Ti, 4070, 4060 Ti, 4060, 4050 <br> RTX 30: 3090 Ti, 3090, 3080 Ti, 3080, 3070 Ti, 3070, 3060 Ti, 3060, 3050 Ti, 3050 <br> RTX 20: 2080 Ti/Super, 2080, 2070 Super, 2070, 2060 Super, 2060 <br> GTX 16: 1660 Ti/Super, 1660, 1650 Super/Ti, 1650 <br> TITAN: Titan RTX, TITAN V |
| Jetson SoC | Jetson AGX Orin, Jetson Orin NX, Jetson Orin Nano |
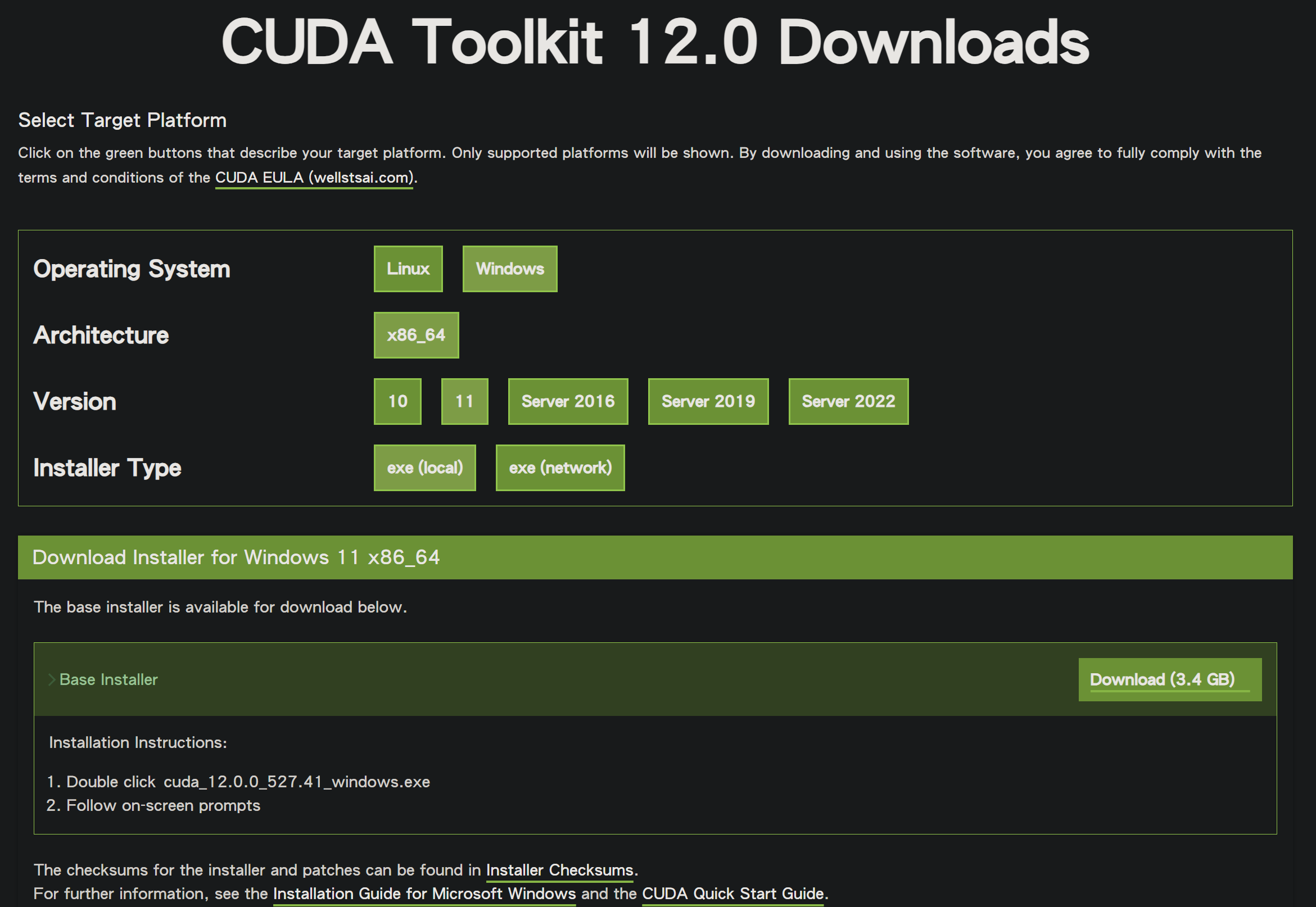
根據官方 CUDA Toolkit 12.0 Downloads 下載連結,選擇對應的作業系統、版本。
在此,我當前下載的是 cuda_12.9.1_576.57_windows.exe,安裝過程全程採用預設設定。
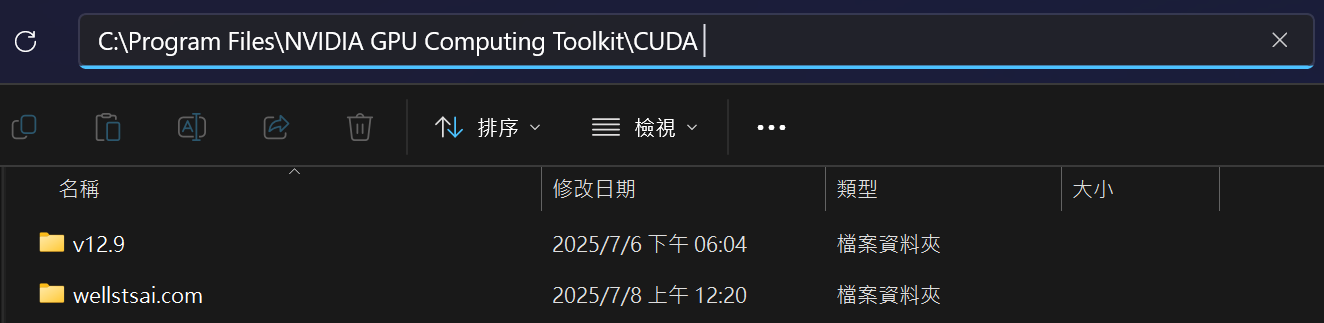
安裝完成後,可於系統目錄 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA 確認 CUDA 是否已安裝完成。
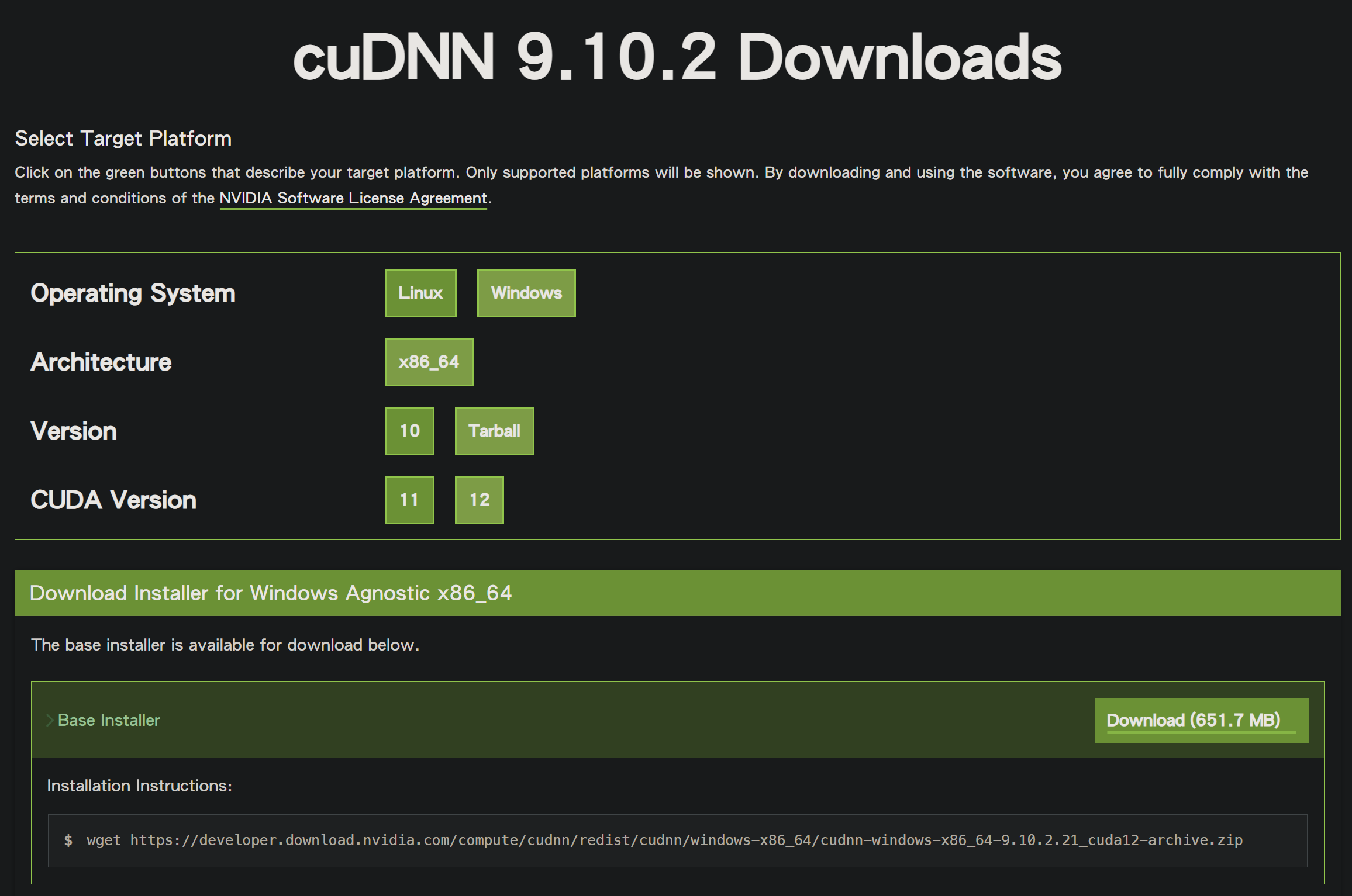
接續於 cuDNN 加速函式庫官方下載頁面 下載相容的 cuDNN 版本。
下載後,取得的為 zip 壓縮檔,檔名為 cudnn-windows-x86_64-9.10.2.21_cuda12-archive.zip。
解壓縮後,將其中的 bin、include、lib 三個資料夾,全部複製到已安裝的 CUDA 目錄下。
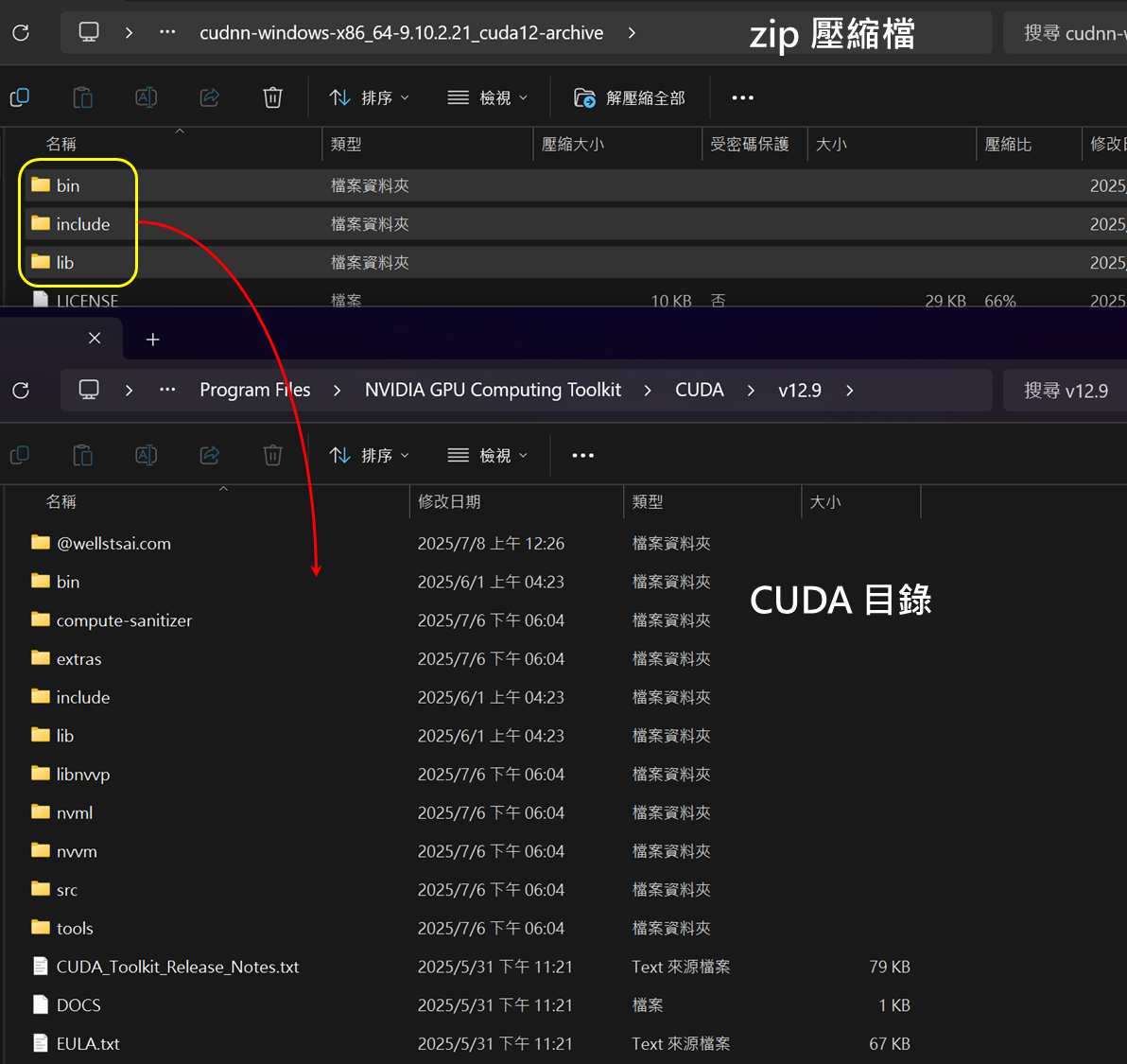
上述 CUDA 及 cuDNN 的安裝與配置即已完成。
使用腳本將影片語音轉文字逐字稿
腳本下載
下載完整套件:generate-srt.zip
解壓縮後,將整個資料夾放在任意目錄即可執行,資料夾內含三個檔案:
- generate-srt.bat(主程式)
- generate-srt.py
- 參數設定.txt
批次檔需要透過外部工具來下載影片,會需要使用到 yt-dlp 下載 YouTube 影片,或是 lux 下載 bilibili 影片。
可以使用 WinGet 進行 yt-dlp 的安裝:
| |
如果有轉換 Bilibili 影片的需求,則需使用 lux。請前往其官方發佈頁面下載 lux.exe 執行檔。
下載完畢後,解壓縮 lux.exe 到 generate-srt 資料夾內即可。
generate-srt.bat
此批次檔負責整體「下載 → 轉寫 → 檔案整理」自動化,重點邏輯包括:
設定區段(⚠️ 首次使用需要根據電腦進行調整)
- whisperModel:指定 Faster-Whisper 模型大小(tiny/base/small/medium/large-v3/turbo)
- whisperDevice:運算設備(cpu/cuda)
- whisperTask:任務模式(transcribe:轉寫/translate:翻譯)
- computeType:精度類型(float16/int8_float16/…)
- openEditor:轉寫完成後開啟字幕檔的編輯器(none/notepad/code)
- autoLoop:是否自動循環處理多支影片(true/false)
環境檢查
- 檢查 yt-dlp、lux 下載器是否安裝或存在於當前目錄
- 檢查 Python 是否可用、並能 import faster_whisper
- 檢查同層目錄是否含有 generate-srt.py
使用 yt-dlp 或 lux 下載影片後,將影片路徑傳給 generate-srt.py 並輸出為字幕檔
最終使用文字編輯器開啟字幕檔
generate-srt.py
此 Python 腳本採用 Faster-Whisper 套件執行語音辨識。其中核心參數可經由外部傳遞。基本上這個檔案不需要進行任何修改。
參數設定.txt
檔案說明所有可調整參數、範例用法與建議設定,內容示例如下:
| |
⚠️ 要開始使用前,務必根據自己電腦硬體進行修改 bat 批次檔,並將修改後結果更改於 generate-srt.bat 的同名變數區段。
whisperModel=turbo,是兼具轉換結果與性能,電腦性能差的可改為 base 或是 tiny。
whisperDevice=cpu,如果已經安裝 CUDA 支援,可以改為 cuda,轉換時間會大幅下降。
openEditor=none,想要轉換完畢自動開啟字幕檔,可以設定為 notepad 或是 code。
使用範例
請先修改
generate-srt.bat裡面的全域變數,如果已設定好 GPU 支援請改為SET "whisperDevice=cuda",可以加快轉換速度。直接滑鼠點兩下
generate-srt.bat,系統將自動檢查執行環境是否符合需求。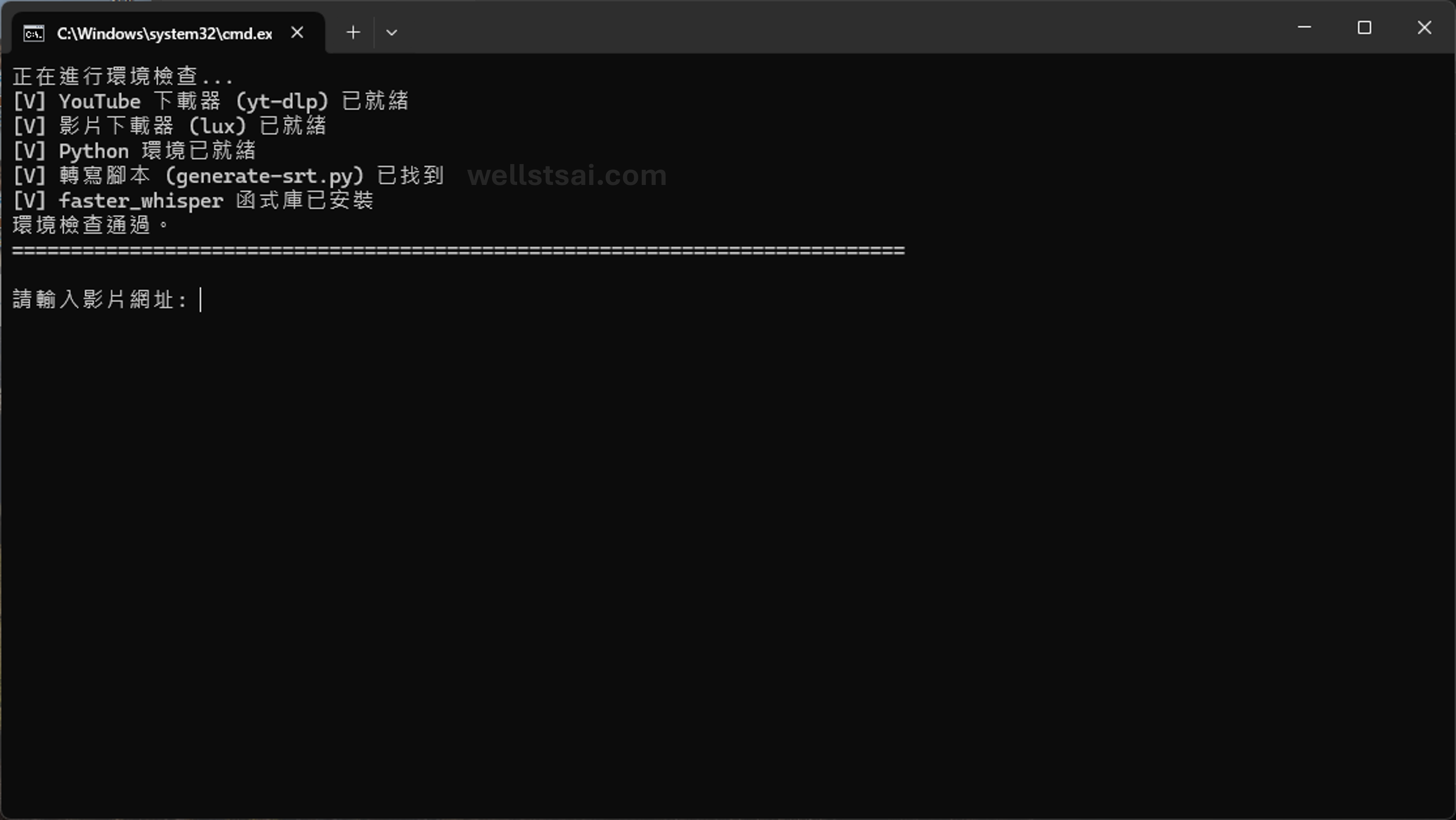
輸入 Youtube 網址,以 《台江國家公園-黑面琵鷺保育及棲息環境》 為例子。本身影片為內嵌字幕,且不提供其他語言的字幕。
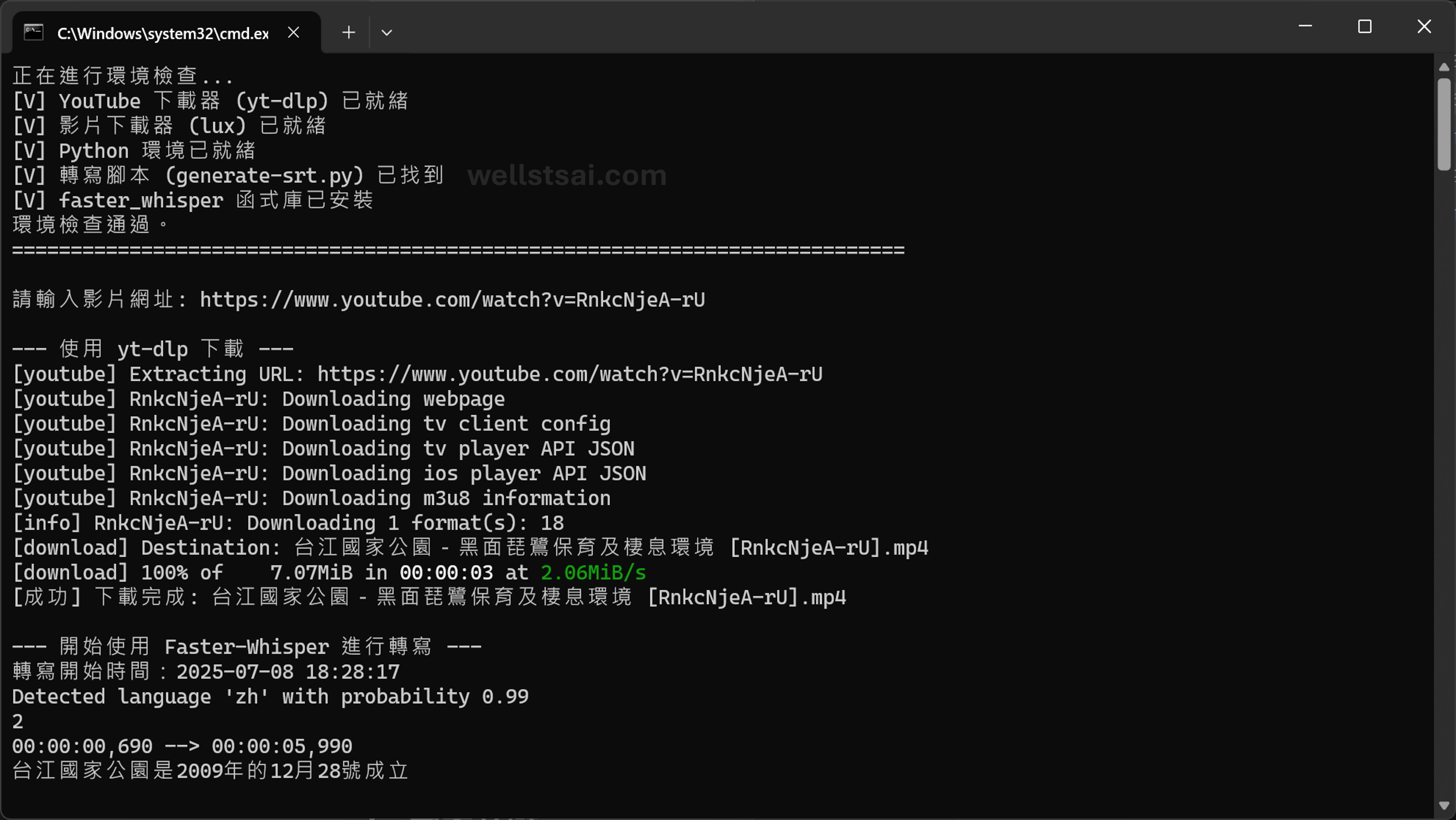
轉換完成後,可於
output資料夾中找到產生之.srt字幕檔。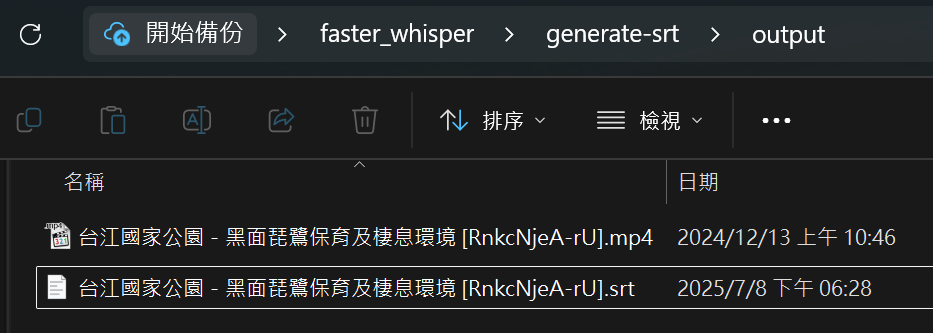
逐字稿轉換結果:
| |
獨立轉換本地檔案
若不需透過 bat 檔下載影片,且已具備本地端音訊檔案,可直接執行下列指令進行字幕轉換:
| |
結論
將影音內容轉換為文字後,可以將這些文字逐字稿提交給大型語言模型(如 ChatGPT 或 Gemini)進行摘要、分析、或是重點整理。這個步驟能幫助我們在短時間內掌握影片的核心資訊,有效過濾冗長或離題的內容,大幅提升資訊獲取效率。
我在測試上發現 base 輸出內容蠻多不正確的,容易把專有名詞輸出錯誤,但丟給 GPT 分析統整是沒什麼大問題。而 turbo 與 large-v3 我個人覺得差不多,但 turbo 勝在轉換速度極快。所以日常使用上基本會以 turbo 為主。
最後分享兩台電腦,針對 18 分鐘影片轉換結果,一台使用 NVIDIA 的 GPU,另一台純 CPU 的時間比較供有需要的人參考。
| 硬體組態 | 模型版本 | GPU 使用 | 轉檔耗時 |
|---|---|---|---|
| NVIDIA RTX 3060 Ti | base | 是 | 01 分 16 秒 |
| NVIDIA RTX 3060 Ti | large-v3-turbo | 是 | 01 分 42 秒 |
| NVIDIA RTX 3060 Ti | large-v3 | 是 | 06 分 43 秒 |
| AMD Ryzen 5 3500X | base | 否 | 03 分 17 秒 |
| AMD Ryzen 5 3500X | large-v3-turbo | 否 | 11 分 29 秒 |