
Introduction
After recording a video, how can you quickly add subtitles?
Or, after recording a meeting conversation or interview on an iPhone, how do you convert it into a readable text transcript?
When a video’s content is too complex or there’s a language barrier, how can you feed it to an AI for a structured summary, complete with causes and effects?
All the needs above can be met by using OpenAI’s open-source Whisper automatic speech recognition model, or its high-efficiency derivative project, Faster-Whisper. By deploying and running it locally, you can achieve one-click video/audio to text transcription, subtitle generation, and subsequent content analysis.
What is Whisper?
Whisper is an automatic speech recognition (ASR) system officially released and open-sourced by OpenAI in September 2022. As of 2025, Whisper has been available for nearly three years.
Main Features
Speech-to-Text: Automatically recognizes and converts speech content from recordings, videos, etc., into a text transcript.
Multi-language Support: Supports over 57 languages (such as Chinese, English, Japanese, French, etc.) and has automatic language detection capabilities. The underlying model is actually trained on data from 98 languages using weak supervision, but the official guarantee of support is limited to the 57 languages with a word error rate below 50%.
Automatic Language Recognition: The model can automatically determine the language being spoken without needing it to be specified beforehand.
Powerful Fault Tolerance: Maintains high recognition accuracy even with poor audio quality, heavy accents, or background noise.
Technical Features
Deep Learning Model: Utilizes a Transformer architecture and is trained with weak supervision on a large-scale, multi-language dataset of speech-to-text pairings.
Open-Source and Available: The source code and model weights are freely available on GitHub, making it convenient for researchers and developers to perform secondary development and customization.
Cross-Platform Support: Can be deployed on various operating systems, including Windows, macOS, and Linux.
Multiple Model Sizes: Offers various model configurations, from
tinytolarge-v3,turbo, allowing users to choose based on their resource and accuracy requirements.
Use Cases
Automatic Video Subtitle Generation: Quickly generate video transcripts and subtitle files (SRT/TXT).
Automated Meeting Minutes: Transcribe audio from online/offline meetings, reducing the time spent on manual organization.
Voice Search and Voice Control: Supports use cases like voice queries and command recognition.
Podcast and Interview Transcription: Quickly convert long-form audio content into text transcripts for easier content management and retrieval.
Other Versions
In addition to the original Whisper model, the community has developed several derivative projects to meet different performance and functional needs:
faster-whisper: Based on the Whisper architecture but rewritten with CTranslate2 as the inference engine. It significantly improves execution speed and resource efficiency, making it suitable for applications requiring high throughput or real-time transcription.
WhisperX: Builds on faster-whisper by adding advanced features like batch inference, forced alignment, speaker diarization, and voice activity detection (VAD). It is particularly useful for precise transcription and analysis of long audio files or recordings with multiple speakers.
Whisper.cpp: A super-lightweight C/C++ implementation of the Whisper model. It can run locally offline on various edge devices (like laptops, mobile phones, IoT) with a fast startup time, making it ideal for scenarios with high demands for real-time performance and portability.
Previously, I used the official OpenAI Whisper for transcribing video subtitles. However, I later discovered that with the same hardware resources, faster-whisper not only achieves comparable or even better recognition accuracy but also significantly reduces computation time. Therefore, this tutorial will prioritize using faster-whisper. If higher alignment accuracy or multi-speaker analysis is needed in the future, evaluating WhisperX would be the next step.
Deploying faster-whisper Locally
Install Python
You need Python 3.9 or a newer version. Here, we’ll install it directly using WinGet:
| |
Check the version with python -V. If a version number is returned, the installation was successful:
| |
Install faster-whisper
| |
Install CUDA Toolkit 12 and cuDNN (Optional)
⚠️ This step is only for systems equipped with an NVIDIA graphics card that supports CUDA.
Using a CUDA-supported GPU can dramatically accelerate the model’s processing workflow and significantly reduce the time required. Below is a summary of NVIDIA GPU models that support CUDA:
| Category | Models |
|---|---|
| Data Center & Superchips | B200, B100, GH200, H200, H100, L40S, L40, L4, A100, A40, A30, A16, A10, A2, T4, V100 |
| Workstation & Pro Cards | RTX PRO 6000, RTX PRO 5000, RTX PRO 4500, RTX PRO 4000, RTX 6000, RTX 5000, RTX 4500, RTX 4000, RTX 2000, RTX A6000, RTX A5500, RTX A5000, RTX A4500, RTX A4000, RTX A2000, Quadro RTX 8000/6000/5000/4000, Quadro GV100, Quadro T-Series |
| GeForce | RTX 50: 5090, 5080, 5070 Ti, 5070, 5060 Ti, 5060 <br> RTX 40: 4090, 4080, 4070 SUPER/Ti, 4070, 4060 Ti, 4060, 4050 <br> RTX 30: 3090 Ti, 3090, 3080 Ti, 3080, 3070 Ti, 3070, 3060 Ti, 3060, 3050 Ti, 3050 <br> RTX 20: 2080 Ti/Super, 2080, 2070 Super, 2070, 2060 Super, 2060 <br> GTX 16: 1660 Ti/Super, 1660, 1650 Super/Ti, 1650 <br> TITAN: Titan RTX, TITAN V |
| Jetson SoC | Jetson AGX Orin, Jetson Orin NX, Jetson Orin Nano |
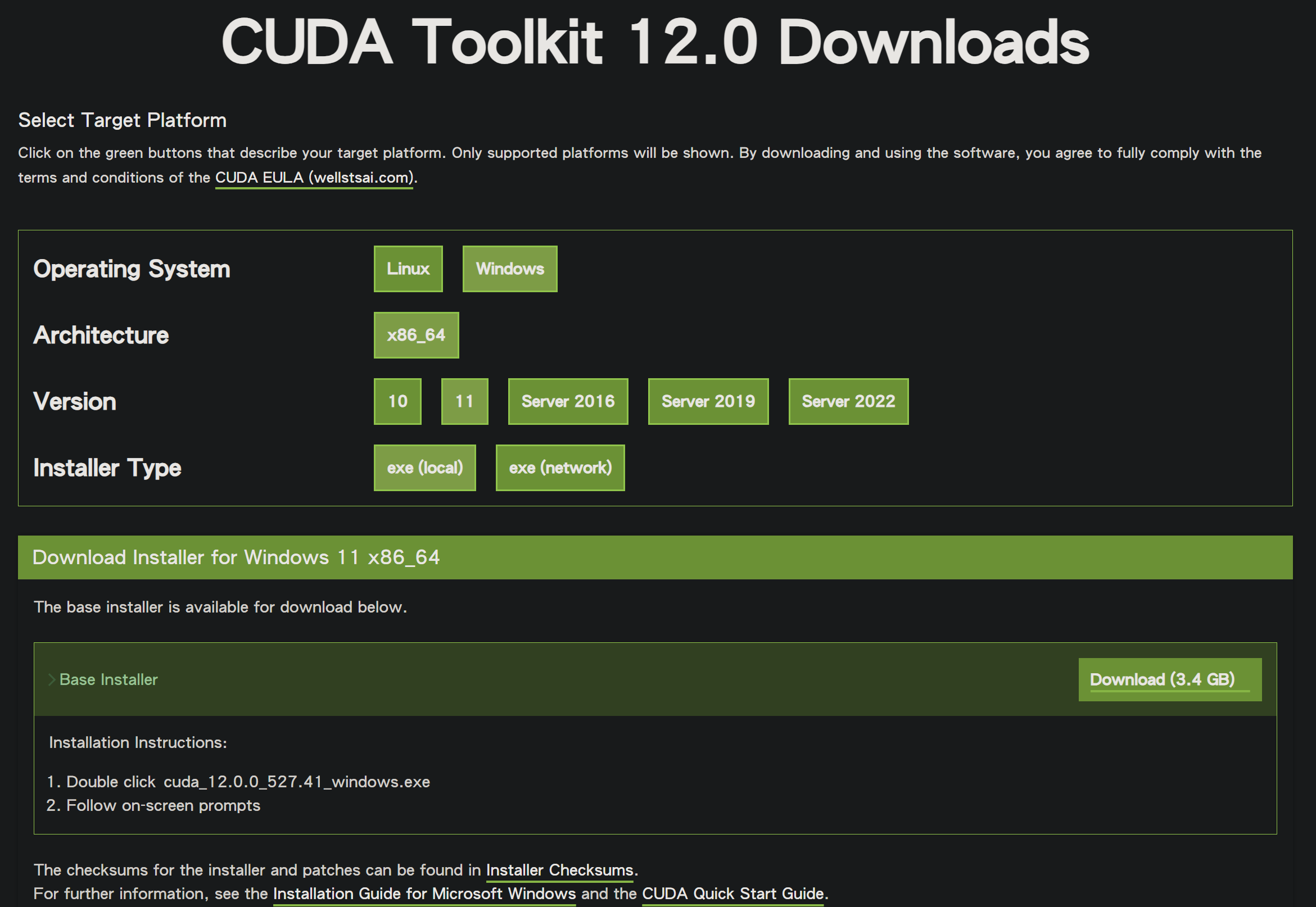
Go to the official CUDA Toolkit 12.0 Downloads link and select the corresponding operating system and version.
In this case, I am currently downloading cuda_12.9.1_576.57_windows.exe. I will use the default settings throughout the installation process.
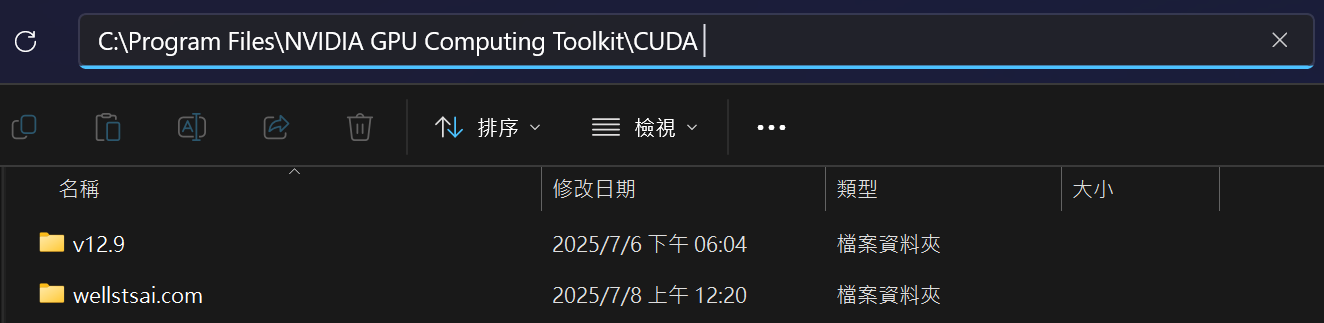
After installation is complete, you can check if CUDA has been installed in the system directory C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA.
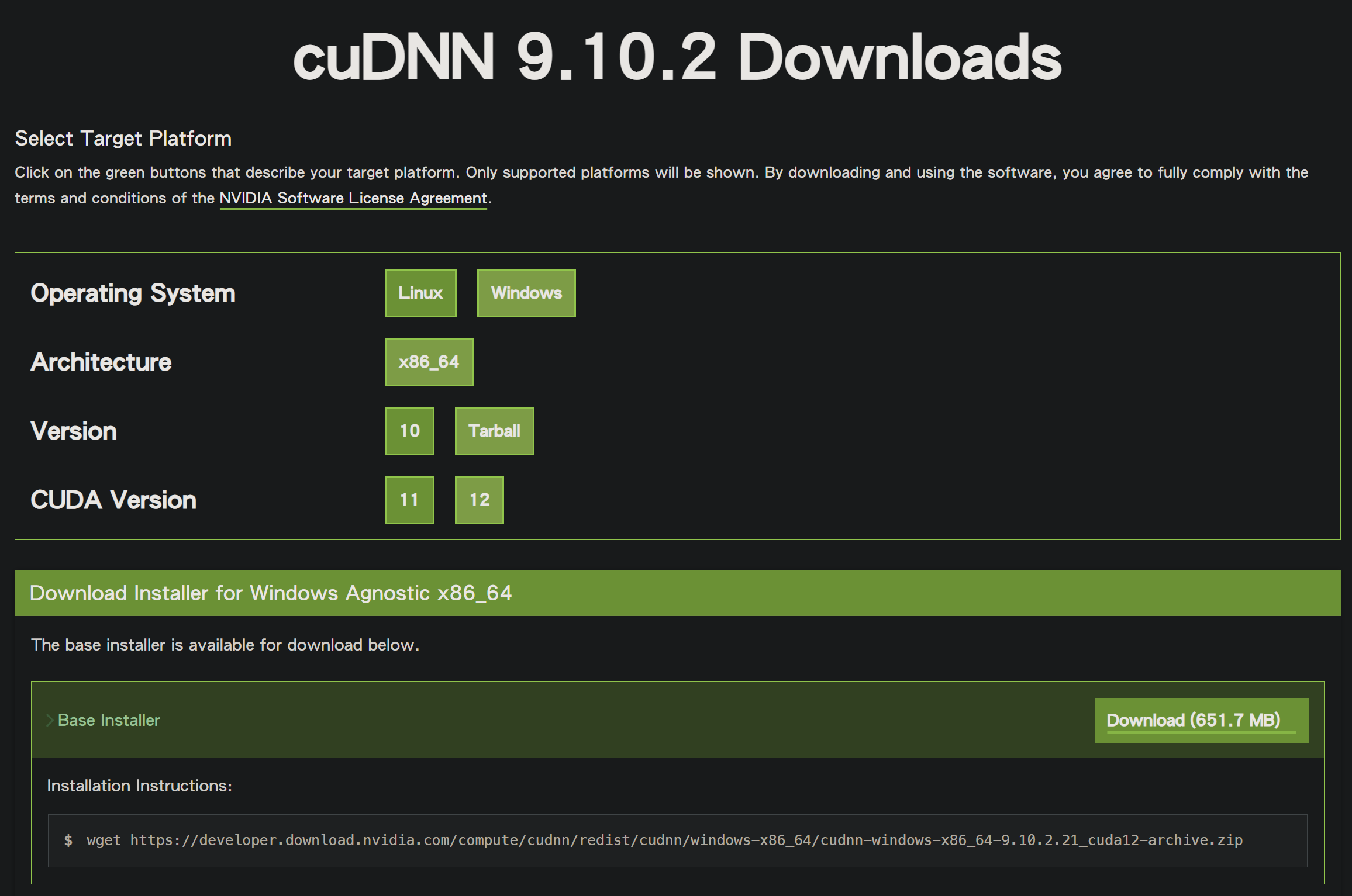
Next, go to the official cuDNN accelerated library download page to download a compatible cuDNN version.
After downloading, you will get a zip archive named cudnn-windows-x86_64-9.10.2.21_cuda12-archive.zip.
After unzipping, copy the bin, include, and lib folders into the already installed CUDA directory.
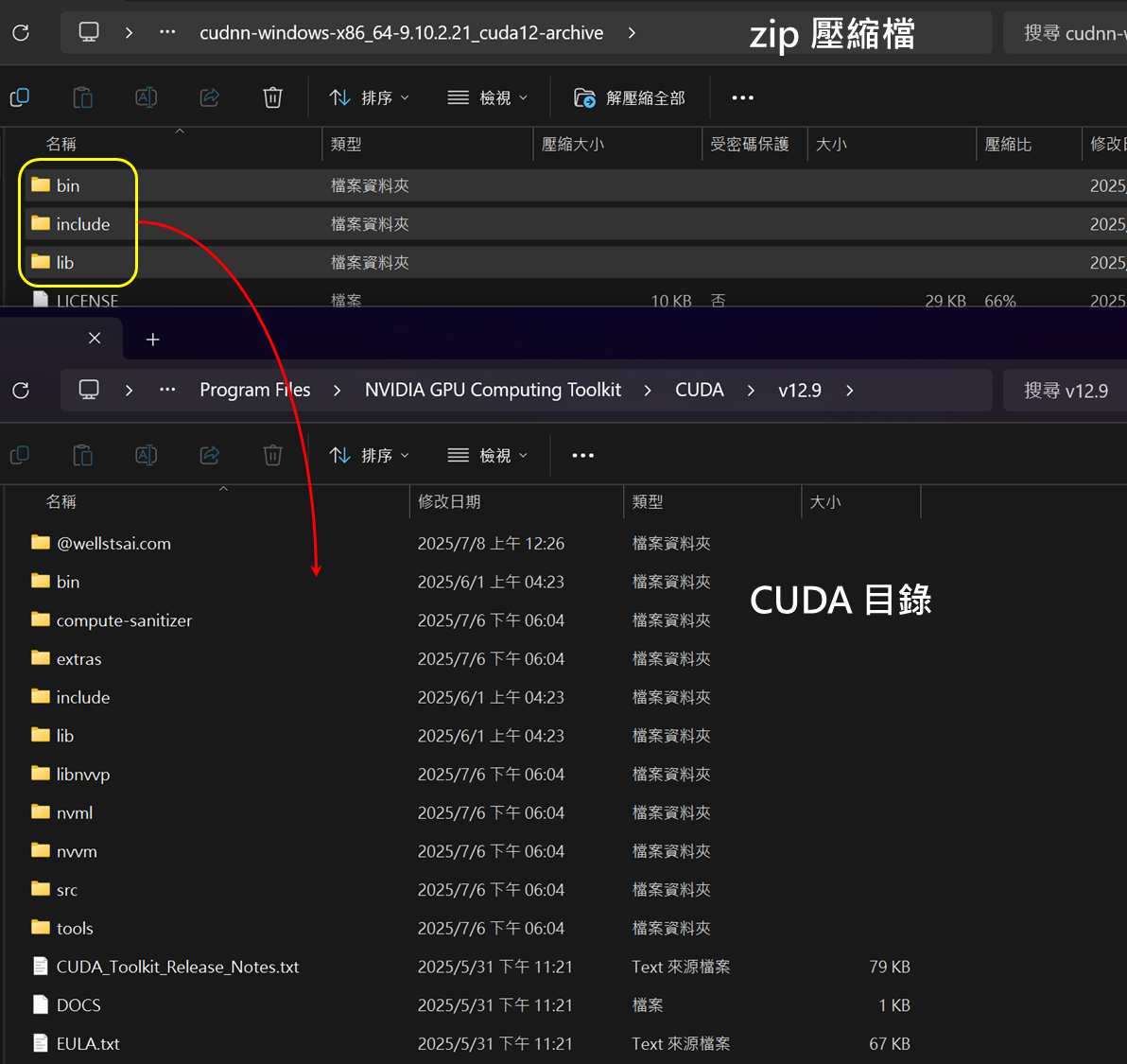
The installation and configuration of CUDA and cuDNN are now complete.
Using the Script to Transcribe Video/Audio to a Transcript
Script Download
Download the complete package: generate-srt.zip
After unzipping, you can place the entire folder in any directory to run it. The folder contains three files:
- generate-srt.bat (Main program)
- generate-srt.py
- parameters.txt (參數設定.txt)
The batch file needs external tools to download videos. It will require yt-dlp to download YouTube videos or lux to download Bilibili videos.
You can use WinGet to install yt-dlp:
| |
If you need to convert Bilibili videos, you will need lux. Please go to its official release page to download the lux.exe executable.
After downloading, unzip lux.exe into the generate-srt folder.
generate-srt.bat
This batch file is responsible for the entire “Download → Transcribe → File Organization” automation. Key logic includes:
Configuration Section (⚠️ Needs to be adjusted based on your computer on first use)
whisperModel: Specify the Faster-Whisper model size (tiny/base/small/medium/large-v3/turbo)whisperDevice: Computation device (cpu/cuda)whisperTask: Task mode (transcribe/translate)computeType: Precision type (float16/int8_float16/…)openEditor: The editor to open the subtitle file after transcription (none/notepad/code)autoLoop: Whether to automatically loop to process multiple videos (true/false)
Environment Check
- Checks if the
yt-dlpandluxdownloaders are installed or exist in the current directory. - Checks if Python is available and if
faster_whispercan be imported. - Checks if
generate-srt.pyis in the same directory.
- Checks if the
Uses
yt-dlporluxto download the video, then passes the video path togenerate-srt.pyto output a subtitle file.Finally, opens the subtitle file with a text editor.
generate-srt.py
This Python script uses the Faster-Whisper package to perform speech recognition. Its core parameters can be passed externally. You generally do not need to modify this file.
parameters.txt (參數設定.txt)
This file explains all adjustable parameters, provides usage examples, and recommended settings. Here is a sample of its content:
| |
⚠️ Before you start, you must modify the batch file according to your computer’s hardware. Apply the changes to the corresponding variable section in
generate-srt.bat.
whisperModel=turbooffers a good balance between results and performance. For less powerful computers, you can change it tobaseortiny.
whisperDevice=cpu. If you have already set up CUDA support, you can change this tocuda, which will significantly reduce the conversion time.
openEditor=none. If you want the subtitle file to open automatically after conversion, you can set this tonotepadorcode.
Usage Example
First, modify the global variables in
generate-srt.bat. If you have GPU support configured, change it toSET "whisperDevice=cuda"to speed up the conversion.Double-click
generate-srt.bat, and the system will automatically check if the execution environment meets the requirements.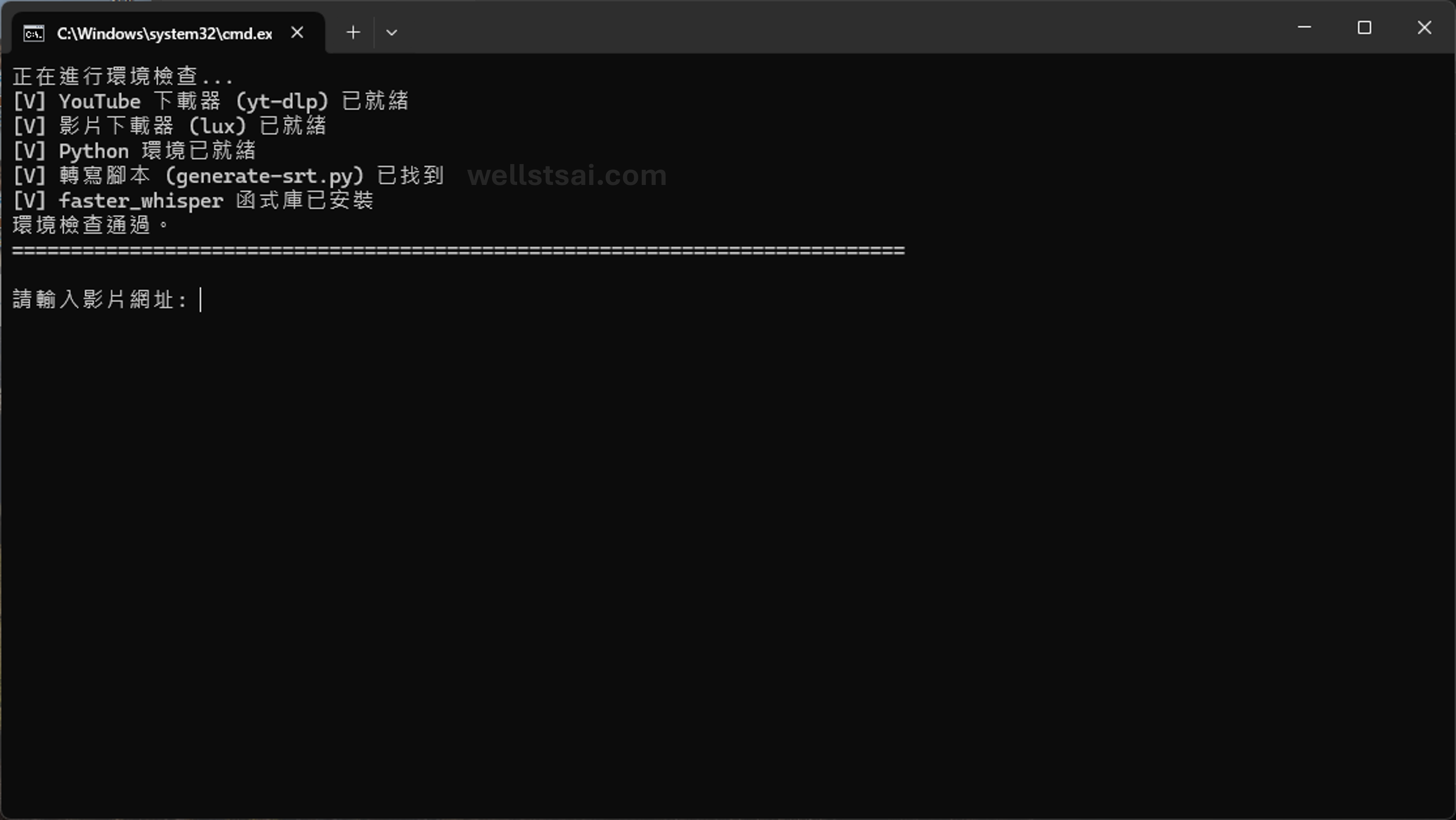
Enter a YouTube URL, for example, “Taijiang National Park – Conservation and Habitat of the Black-faced Spoonbill”. This video has embedded subtitles and does not provide subtitles in other languages.
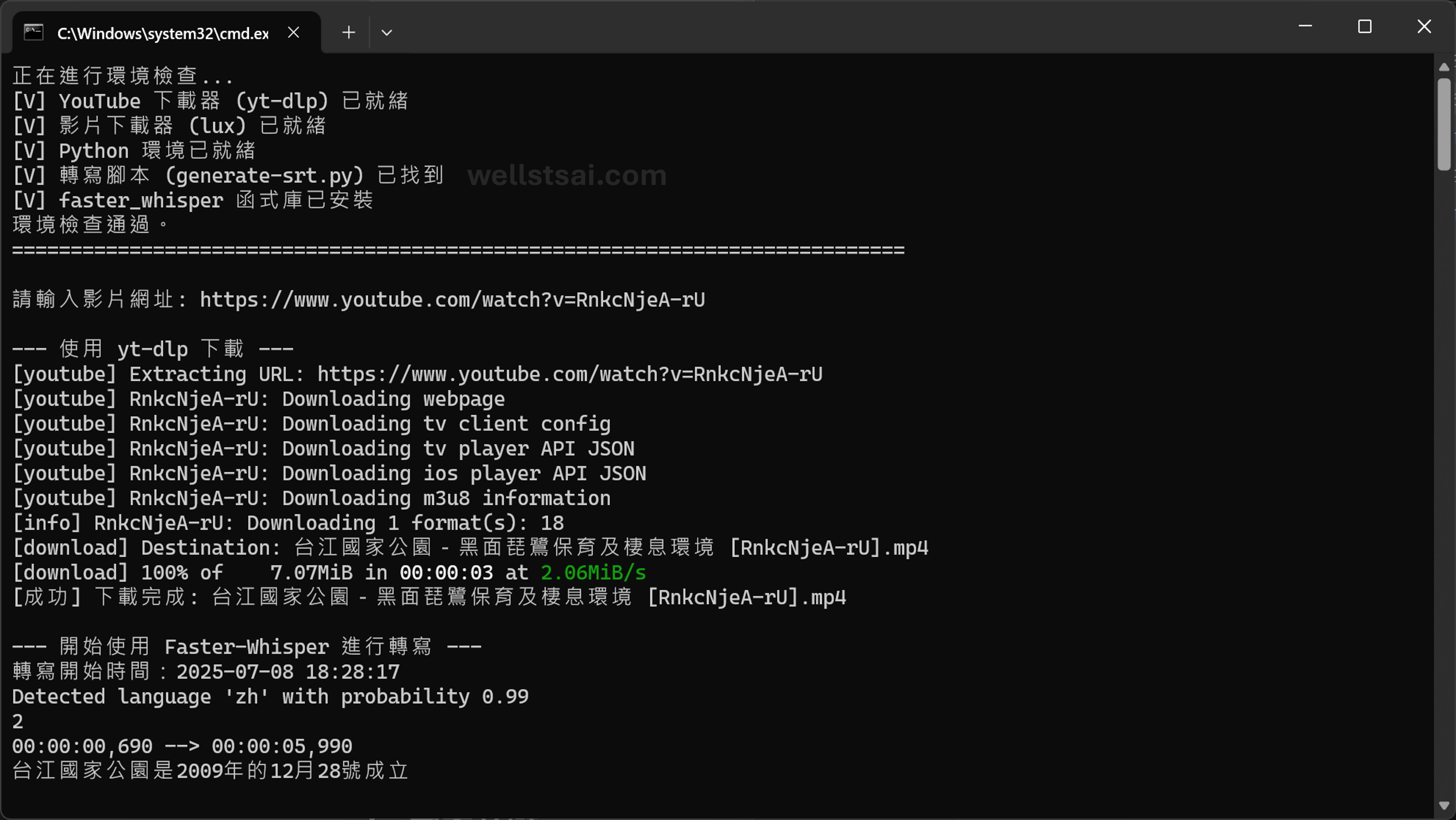
After the conversion is complete, you can find the generated
.srtsubtitle file in theoutputfolder.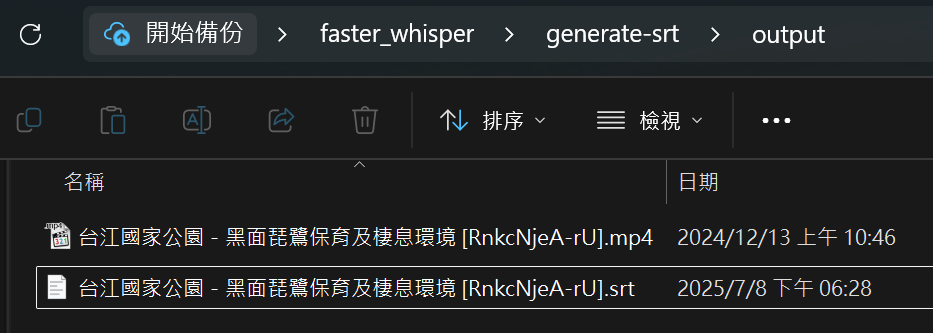
Transcript conversion result:
| |
Independently Transcribing Local Files
If you don’t need to download a video via the bat file and already have a local audio file, you can directly execute the following command to transcribe subtitles:
| |
Conclusion
After converting audio/video content to text, you can submit these transcripts to a large language model (like ChatGPT or Gemini) for summarization, analysis, or key point extraction. This step helps in grasping the core information of the video in a short amount of time, effectively filtering out lengthy or off-topic content and significantly improving information retrieval efficiency.
In my tests, I found that the base model’s output contained quite a few inaccuracies and tended to misspell proper nouns, but it was generally fine for analysis and summarization by GPT. As for turbo and large-v3, I personally feel they are quite similar, but turbo has the advantage of extremely fast conversion speeds. Therefore, for daily use, I primarily use turbo.
Finally, I’m sharing a comparison of the conversion results for an 18-minute video on two different computers—one using an NVIDIA GPU and another with only a CPU—for anyone who might find it useful.
| Hardware Configuration | Model Version | GPU Used | Processing Time |
|---|---|---|---|
| NVIDIA RTX 3060 Ti | base | Yes | 01 min 16 sec |
| NVIDIA RTX 3060 Ti | large-v3-turbo | Yes | 01 min 42 sec |
| NVIDIA RTX 3060 Ti | large-v3 | Yes | 06 min 43 sec |
| AMD Ryzen 5 3500X | base | No | 03 min 17 sec |
| AMD Ryzen 5 3500X | large-v3-turbo | No | 11 min 29 sec |